如何追踪大规模分布式系统
在阅读如何使用OpenTracing标准,监控大规模分布式系统之前,确保你已经阅读过Specification overview章节
Spans 和它们之间的关系
实现OpenTracing完成分布式追踪的两个基本概念就是Spans和Relationships(span间关系):
Span 是系统中的一个逻辑工作单元,包含这个工作单元启动时间和执行时间。在一条追踪链路中,各个span与系统中的不同组件有关,并体现这些组件的执行路径。
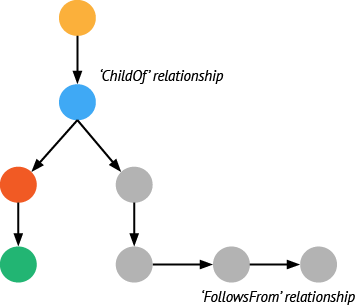
Relationships 是span间的连接关系。一个span可以和0-n个组件存在因果关系。这种关系是的各个span被串接起来,并用来帮助定位追踪链路的关键路径。
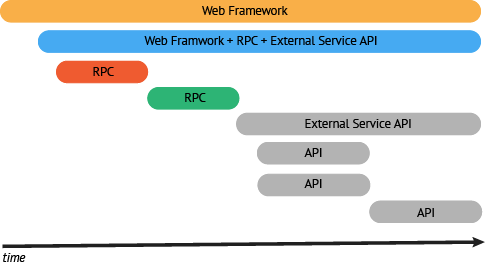
你所期待的结束状态,是获取你所有组件的span,以及它们之间的关系。当开始建立你的分布式追踪系统时,最好的方法是从服务框架(如:RPC层)或者其他和复杂执行路径有关的组件开始。
你可以从使用支持OpenTracing标准的服务框架开始 (如:gRPC)。但是,如果你不支持OpenTracing的框架,你可以阅读IPC/RPC Framework Guide章节。
专注高价值区域
如上面提到的,从RPC层和你的web框架开始构建追踪,是一个好方法。这两部分将包含事务路径中的大部分内容。
下一步,你应该着手在没有被服务框架覆盖的事务路径上。为足够多的组件增加监控,为高价值的事务创建一条关键链路的追踪轨迹。
你监控的首要目标,是基于关键路径上的span,寻找最耗时的操作,为可量化的优化操作提供最重要的数据支持。例如,对于只占用事务时间1%的操作(一个大粒度的span)增加更细粒度的监控,对于你理解端到端的延迟(性能问题)不会有太大意义。
先走再跑,逐步提高
如果你正在构建你的跨应用追踪系统实现,使用这套系统建立高价值的关键事务与平衡关键事务和代码覆盖率的概念。最大的价值,在于为关键事务生成端到端的追踪。可视化展现你的追踪结果是非常重要的。它可能帮助你确定那块区域(代码块/系统模块)需要更细粒度的追踪。
一旦你有了端到端的监控,你很容易评估在哪些区域增加投入,进行更细粒度的追踪,并能确定事情的优先级。如果你开始深入处理监控问题,可以考虑哪些部分能够复用。通过这些复用建立一套可以在多个服务间服用的监控类库。
这种方法可以提供广泛的覆盖(如:RPC,web框架等),也能为关键业务的事务增加高价值的埋点。即使有些埋点(生成span)的代码是一次性工作,也能通过这种模式发现未来工作的优先级,优化工作效率。
示例实例
下面的例子让上述的概念更具体一些:
在这个例子中,我们想追踪一个,由手机端发起,调用了多个服务的调用链。
首先,我们必须说明这个事务的大体情况。在我们的例子中,事务如下所示:
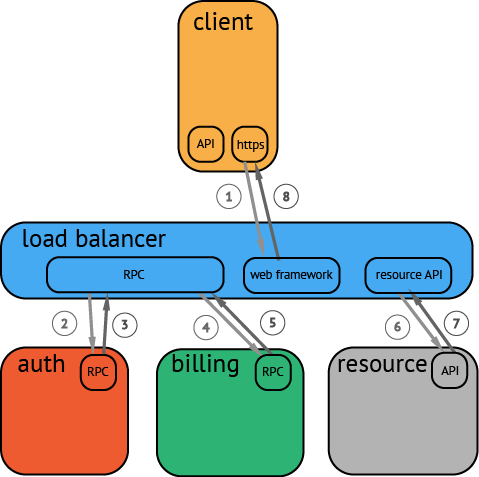
一个客户通过手机客户端向web发起了一个HTTP请求,产生一个复杂的调用流程:mobile client (HTTP) → web tier (RPC) → auth service (RPC) → billing service (RPC) → resource request (API) → response to web tier (API) → response to client (HTTP)
现在,我们对事务的大概情况了解,我们去监控一些通用的协议和框架。最好的选择是从RPC服务框架开始,这将是收集web请求背后发生的调用情况的最好方式。(或者说,任何在分布式过程中发生的问题,都会在直接体现在RPC服务中)
下一个重点监控的组件应该是web框架。通过增加web框架的监控,我们能够得到一个端到端的追踪链路。虽然这点追踪链路有点粗,但是至少,我们的追踪系统获取到了完整的调用栈。
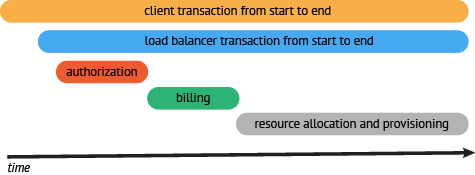
通过上面的工作,我们可以看到所需的调用链,并评估我们细化哪一块的追踪。在我们的例子中,我们可以看到,请求中最耗时的操作时获取资源的操作。所以,我们应该细化这块的监控粒度,监控资源定位内部的组件。一旦我们完成资源请求的监控,我们可以看到资源请求被分解成下图所示的情况:
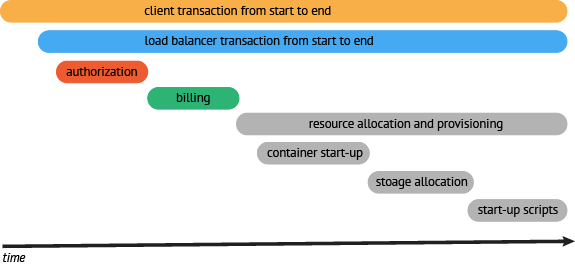 resource request (API) → container startup (API) → storage allocation (API) → startup scripts (API) → resource ready response (API)
resource request (API) → container startup (API) → storage allocation (API) → startup scripts (API) → resource ready response (API)一旦我们完整资源组件的追踪,我们可以看到大量的时间消耗在提供上,下一步,我们深入分析,如果可能,我们优化资源获取程序,使用并行处理替代串行处理。
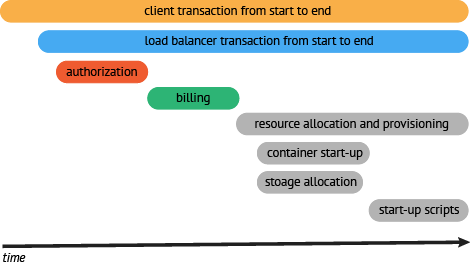
现在我们有了一条基于端到端调用流程的可视化展现以及基线,我们可以为这个服务建立明确的SLO。另外,为内部服务建立SLO,可以成为对服务正常和错误运行的时间的讨论的基础。
下一次跌倒,我们回到最顶层的追踪,去寻找下一个长耗时的任务,但是没有明细展现,这时需要更细粒度的追踪。如果展现的粒度已经足够,我们可以进行下一个关键事务的追踪和调优处理了。
重复上述步骤.